After more than 10 years at The Wall Street Journal, I took the buyout offered to the newsroom this fall. My decision is bittersweet: Although I’ll miss my colleagues, I am excited for the opportunities coming my way this year.
I will be spending time with family and will start 2017 as interim communications director at the new Knight Institute for the First Amendment at Columbia University. The institute, funded jointly by the Knight Foundation and Columbia, works to protect and expand freedoms of speech and the press in the digital age.
As the Internet has shaken the media industry, traditional outlets have been less able to undertake First Amendment litigation. Simultaneously, changes in communications technology are raising First Amendment questions about things such as surveillance and the freedom of Internet platforms. The institute will aim to help solve these problems in favor of greater press freedoms. I’ll be working with them to get their website launched, get on social media, develop an introductory symposium and produce initial research and commentary.
I also will do some freelance work this year, so stay tuned. My plan is to head back to full-time journalism work late in 2017.
I’ve written here before about “empirical journalism” and the idea that reporters don’t have to wait for experts to conduct studies that might help readers. Continuing with that idea, recently I worked with a computer researcher to evaluate the security of popular Wi-Fi routers for a story.
The novel survey showed that half the devices arrived with known, previously documented security weaknesses. Only two required users to change from the default password–something that computer security pros have been demanding for many years. Half didn’t let users easily check for new software during the standard setup process. Instead, users had to search on the Web themselves or run optional programs. Two actually told users that updated software wasn’t available, when in fact it was, and one directed users to download new software that itself had a severe, documented security flaw.
Security of Wi-Fi routers might not sound too sexy. But routers already have been used in attacks to disrupt networks or siphon people’s data. And they’re one of many types of devices that are being connected to the Internet but that don’t receive the security attention of PCs. Trust me, these devices are poised to become more important to hackers in the future; almost every security pro I talk with sees things like this as a weak link.
Over the past year, I’ve been increasingly asked to speak about computer security for journalists–specifically, how reporters can avoid surveillance by governments and help protect their sources.
Unfortunately, many people seem to think there’s some kind of magic bullet that will protect reporter-source conversations, and that all our problems would be solved if reporters could simply learn to use encryption. But encryption isn’t as magic bullet; there’s much more to source protection than encrypted email.
If you’re here thinking you’re going to find an easy solution–or any particular solution at all, really–I’m sorry. I don’t have one.
But I’ve been speaking about this subject enough now that I have a few tips and tools I’d like to put together in one place.
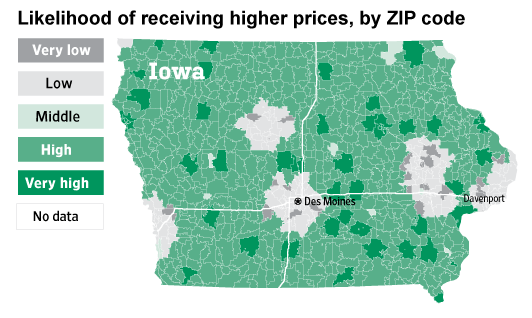
A look at prices on Staples.com when connecting from different areas in Iowa
Note: After publication of this post, the Journal’s graphics server was hacked. Graphics associated with this story may not be available.
For some people, the price of a Swingline stapler on the Staples.com website is $15.79, while for others, it’s more than a dollar cheaper, at $14.29. This is for the same stapler, at the same time, with the same shipping costs and taxes.
So what’s going on?
My colleague Jeremy Singer-Vine and I found that the Staples website was displaying different prices to people after it had estimated their locations — and that, specifically, Staples appeared to be offering discounts to people who were closer to rival brick-and-mortar stores.
The story, which was in The Wall Street Journal in December, identified several companies that consistently adjusted prices and offers online based on a shopper’s characteristics, including location. It was a fun story to write and to report. But perhaps the most important part of the reporting of this story is actually found in the technical methodology, which appeared only online.
This reporting was primarily a technical feat by Jeremy and another colleague, Ashkan Soltani. The two of them built custom software to analyze pricing on sites. And on Staples, Jeremy simulated visits from all the more than 42,000 ZIP Codes in the U.S. and analyzed the results statistically.
So why is this important? Because this type of work allows us as journalists to develop theories and test them ourselves. Without this, we would have to rely on others to tell us what’s happening — when too often, people simply don’t want anyone to know what’s going on.
Sure, it’s not possible to do this type of journalism on every subject. But I find it helpful to think regularly about whether a subject might benefit from data gathering and analysis.
And I’ve found that empirical journalism particularly helpful when studying the Internet. It’s something my editor Julia Angwin pioneered in the What They Know series, which reshaped the debate on digital privacy precisely because it produced empirical evidence in addition to a compelling story.
Empirical journalism isn’t a new idea, of course. For decades, journalists have developed stories by painstakingly investigating and compiling information. Recently, data-driven journalism has produced great work as well. But the type of reporting in the What They Know series is slightly different; it involves not just analysis of an existing dataset, but rather the gathering of entirely new data. And it’s the future of technology coverage.
This fall, The Wall Street Journal obtained a set of documents from a secretive trade show for surveillance and intelligence tech. The marketing materials reveal an industry that has grown rapidly in the past 10 years to supply the increasing demand from governments.
In addition to the usual articles in print and online, we wanted to give readers a chance to see the documents themselves. To do this, my fellow online journalists Zach Seward and Jeremy Singer-Vine suggested a service called DocumentCloud — part of Investigative Reporters and Editors, a nonprofit organization dedicated to investigative journalism. DocumentCloud lets journalists upload documents, annotate and categorize them and then use them in interactive graphics and the like. Documents are automatically run through an “optical character recognition” system, so they’re easily searched. Readers can view the journalists’ notes or download the original document as well.
As a new user of the system, I found DocumentCloud to be slick and incredibly easy to use. We couldn’t have completed our project so quickly without this tool. There are, however, a few things I’d love to see, including the ability to categorize annotations. This sort of finer control would allow readers to see only annotations related to glossary definitions of words, for example, or notes that correspond to certain stories. The folks at DocumentCloud are regularly updating the features. If you’re a journalist who regularly uses original source material, you should check it out.
Note: Several years after I published this post, the Journal’s graphics server was hacked, and the graphic itself was lost.
The graphic above is part of a project Albert Sun, Zach Seward and I did for The Wall Street Journal that looks at a week’s worth of data from Foursquare — which is a mobile app that lets people “check in” to different locations. This was one of those projects that was done in our “spare time” — of which we have very little — so it took us a few months. Foursquare is still kind of a niche technology, used by only a small percentage of people, but it’s fascinating to see just what information you can get even from people who are willing to freely give up their data.
We looked specifically at New York and San Francisco, two cities with many early Foursquare users. Much of the data showed us what we already knew, for example that people in New York have weekday lunch in Midtown and go out in the Lower East Side on Friday nights. But there were some interesting tidbits as well. Among my favorites: The most disproportionately male locations were gay bars and … tech start-ups. And San Franciscans love coffee shops, while New Yorkers love bars. For more, see our graphic and blog post.
I spent three glorious days at the Strata conference on “big data” earlier this month — in sunny Santa Clara, surrounded by statistics nerds. The confab, put on by the folks at O’Reilly, proved to be fertile ground for potential stories, as well as for new ways to convey them based on data.
But one question still nags me about this field: What is “big data” in the first place? After all, large data sets have been around for years — although it’s true that we’re now talking petabytes instead of lowly terabytes. Something else that isn’t so new: “data mining,” or the parsing of said data to find patterns, often using artificial intelligence. Furthermore, it’s not always the size of the data that matters; the visualization techniques being discussed at Strata, for example, could very well be used with smaller data sets.
What’s new isn’t just the size of the data involved, or even the fact that it’s being analyzed, but how important and accessible it now is. The point is that data are now everywhere, being scattered like so many breadcrumbs. Tyler Bell at O’Reilly Radar has a good post on the many metaphors being used to describe the concept — like “the new oil,” “data deluge” and my personal favorite, “data exhaust.”
Several folks at the conference posed “data science” as an alternative term to “big data,” and I think that works. It certainly broadens the subject and seems more understandable.
 I’ve written here before about “empirical journalism” and the idea that reporters don’t have to wait for experts to conduct studies that might help readers. Continuing with that idea, recently I worked with a computer researcher to evaluate the security of popular Wi-Fi routers for
I’ve written here before about “empirical journalism” and the idea that reporters don’t have to wait for experts to conduct studies that might help readers. Continuing with that idea, recently I worked with a computer researcher to evaluate the security of popular Wi-Fi routers for